
Les chatbots de la GenAI ont du mal à être précis dans les faits
Les chatbots d’IA générative, malgré leurs capacités tape-à-l’œil, achoppent sur ce qui devrait être la tâche la plus facile : fournir des réponses précises à des questions simples. Le test de référence SimpleQA d’OpenAI met ce point en évidence. Imaginez que vous demandiez à un chatbot : « Qui a peint la Joconde ? » ou « En quelle année le Titanic a-t-il coulé ? ». Des questions simples, n’est-ce pas ? Pour les humains, oui. Pour ces modèles, pas vraiment. SimpleQA a été conçu pour tester l’exactitude des faits de manière rigoureuse et reproductible, et les résultats donnent à réfléchir.
Le modèle o1-preview d’OpenAI n’a obtenu qu’une précision de 42,7 % lors de ce test. Le modèle GPT-4o n’était pas loin derrière, avec 38,2 %. Le modèle GPT-4o-mini, plus petit, s’est effondré à 8,6 %. Et OpenAI n’est pas le seul à se débattre. Le Claude-3.5-sonnet d’Anthropic a obtenu des résultats encore plus médiocres, avec seulement 28,9 %. En termes de notation ? Ils ont tous obtenu un F.
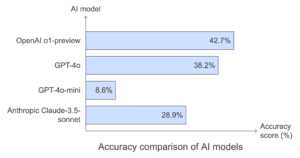
Comparaison de la précision des modèles d’IA
Ces échecs ne découlent pas seulement d’un manque de connaissances. Le problème est plus profond : il s’agit d’hallucinations – qui génèrent avec assurance des réponses incorrectes – et d’un excès de confiance troublant dans les résultats obtenus. Non seulement ces chatbots se trompent, mais ils se trompent avec conviction, et leurs erreurs peuvent être difficiles à repérer.
Le benchmark lui-même met ces modèles dans une situation délicate. SimpleQA pose des questions qui exigent des réponses précises et indiscutables, sans fioritures ni incertitudes. Dans le monde réel, ces lacunes dans la fiabilité des faits pourraient avoir de graves conséquences, que ce soit dans le domaine de l’éducation, du service à la clientèle ou dans tout autre domaine qui s’appuie sur ces outils pour obtenir des réponses rapides et factuelles. Pour l’instant, ces outils présentent des lacunes impressionnantes, ils sont parfaits pour paraître intelligents, mais ils sont souvent loin d’être tout simplement exacts.
Les chatbots sont plus performants lorsqu’ils sont contextualisés et qu’ils répondent à des questions ouvertes.
Les chatbots sont comme des conteurs : donnez-leur une toile et ils peindront un tableau. Donnez-leur une feuille blanche sans instructions et ils se débattront. Le test de référence SimpleQA a exploité ce talon d’Achille en supprimant tout contexte et en posant des questions précises et autonomes. Dans ce format, les chatbots ont eu du mal à trouver des réponses exactes.
Les grands modèles de langage (LLM) se débrouillent très bien avec les questions ouvertes. Ils excellent lorsqu’il s’agit de produire des résumés nuancés, d’explorer des idées abstraites ou de discuter de sujets complexes. Demandez-leur de rédiger un rapport sur les énergies renouvelables ou de résumer un roman, et ils seront dans leur élément. Mais demandez-leur « Quelle est la capitale de la France ? » et ils donneront peut-être une réponse claire – ou la rateront, selon la façon dont la question est formulée.
Le test SimpleQA a mis en évidence cette lacune. Il pénalisait les variations mineures dans les réponses, telles que la couverture ou l’offre d’autres possibilités. Les modèles n’ont tout simplement pas été conçus pour la précision rigide, en noir et blanc, exigée par le test. Considérez-les comme des multitâches conversationnels, et non comme des spécialistes de la réponse unique.
La leçon à en tirer est simple mais puissante : si vous voulez que votre chatbot soit performant, donnez-lui du contexte. Quelques lignes de contexte peuvent faire toute la différence. Les modèles peuvent avoir du mal à répondre à une seule ligne, mais leur capacité à tisser des idées pour en faire des réponses significatives et riches en contexte est leur véritable force. Utilisez-les pour la profondeur, pas pour les futilités, et vous obtiendrez de meilleurs résultats.
Les LLM manquent de compréhension du monde réel et de connaissances structurées
Les modèles d’IA sont comme des encyclopédies qui peuvent parler – impressionnants, mais limités. Des recherches menées par le MIT, Harvard et Cornell révèlent une faille plus profonde : ces modèles ne « connaissent » pas le monde de manière significative. Ils génèrent des réponses basées sur des modèles dans leurs données d’apprentissage, et non sur une carte interne de la façon dont les choses fonctionnent réellement.
Voici un exemple. Les LLM peuvent donner d’excellentes indications routières dans la ville de New York lorsque tout va bien. Mais lorsque les chercheurs ont fermé seulement 1 % des rues de la ville, la précision de ces indications a chuté de près de 100 % à 67 %. Pourquoi ? Contrairement aux humains, ces modèles ne visualisent pas la ville et ne s’adaptent pas aux changements. Ils ne « voient » pas de déviation, ils savent simplement à quoi ressemblaient des scénarios similaires dans le passé.
Il ne s’agit pas d’un problème de navigation. Il reflète une incapacité plus générale à penser de manière flexible ou à détenir des connaissances structurées. Les humains peuvent improviser en cas d’imprévu. L’IA en est incapable. Sa brillance dans les tâches contrôlées s’effondre lorsqu’elle est confrontée à des situations diverses et imprévisibles.
« Traitez les LLM comme des outils et non comme des penseurs. Ils sont puissants pour automatiser les tâches répétitives ou traiter de grands ensembles de données, mais ne sont pas prêts à remplacer l’intuition humaine ou la prise de décision dans le monde réel. L’IA peut imiter l’expertise, mais elle ne peut pas reproduire la compréhension – pas encore. »
Les hallucinations de l’IA posent des risques réels dans des secteurs critiques
Les hallucinations de l’IA ne sont pas anodines. Dans des secteurs comme la santé, les conséquences peuvent être désastreuses. Des outils comme Whisper d’OpenAI sont largement utilisés, notamment pour la transcription médicale. Plus de 30 000 cliniciens et 40 systèmes de santé s’appuient sur des solutions basées sur Whisper, comme Nabla, qui a traité environ sept millions de visites médicales aux États-Unis et en France. Mais voici le problème : ces outils fabriquent souvent des informations.
Une analyse a révélé des hallucinations dans près de 40 % des transcriptions examinées, et nombre d’entre elles ont été qualifiées de nocives ou de préoccupantes. Whisper a même inventé un médicament inexistant, les « antibiotiques hyperactivés ». Imaginez les risques – diagnostics erronés, traitements inappropriés, voire pire – si de telles erreurs ne sont pas contrôlées.
L’ampleur de l’adoption est stupéfiante. Whisper a été téléchargé 4,2 millions de fois à partir de HuggingFace, une plateforme open-source. Alors que des millions de personnes bénéficient de flux de travail plus rapides et plus efficaces, les failles de la technologie sont intégrées dans des processus critiques sans garanties suffisantes.
Pour les dirigeants, la conclusion est claire : il faut agir avec prudence. Les outils pilotés par l’IA comme Whisper sont excellents pour réduire la charge de travail et améliorer l’efficacité, mais leurs résultats doivent être soigneusement validés. Intégrez la redondance dans les flux de travail et prévoyez toujours une supervision humaine lorsque les enjeux sont élevés.
Les utilisateurs doivent aborder les résultats de l’IA avec scepticisme et vérifier les informations.
Les chatbots sont d’excellents compagnons pour le brainstorming, la synthèse et l’idéation. Mais lorsqu’il s’agit de fournir des faits concrets, ils ne sont pas fiables. Chaque résultat doit être considéré comme un point de départ, et non comme une vérité absolue. Cela est particulièrement important pour les professionnels qui utilisent l’IA dans des contextes où les enjeux sont importants.
La vérification est essentielle. Ne vous contentez pas de croire l’IA sur parole, mais comparez-la à des documents originaux ou à des sources dignes de confiance. Des outils comme NotebookLM de Google facilitent ce processus. Par exemple, vous pouvez télécharger un document de recherche dans NotebookLM, puis comparer ses informations avec celles fournies par votre chatbot. C’est un moyen rapide de repérer les erreurs ou les incohérences.
Voici la règle d’or : ne jamais copier-coller les réponses de l’IA dans quelque chose d’important sans l’avoir examiné de près. Le langage généré par l’IA donne souvent l’impression d’être légèrement décalé, qu’il s’agisse de la formulation ou de l’accentuation. Pire encore, le robot peut halluciner et donner avec assurance des informations qui sont tout simplement erronées.
Pour les cadres, cela se résume à un changement d’état d’esprit. L’IA n’est pas là pour remplacer la pensée critique. C’est un outil qui permet de l’amplifier. Utilisez-la pour accélérer la recherche, explorer des idées ou alléger votre charge de travail, mais gardez toujours votre propre expertise dans le siège du conducteur. C’est lorsque vous associez le jugement humain aux capacités de l’IA que les choses deviennent intéressantes.




